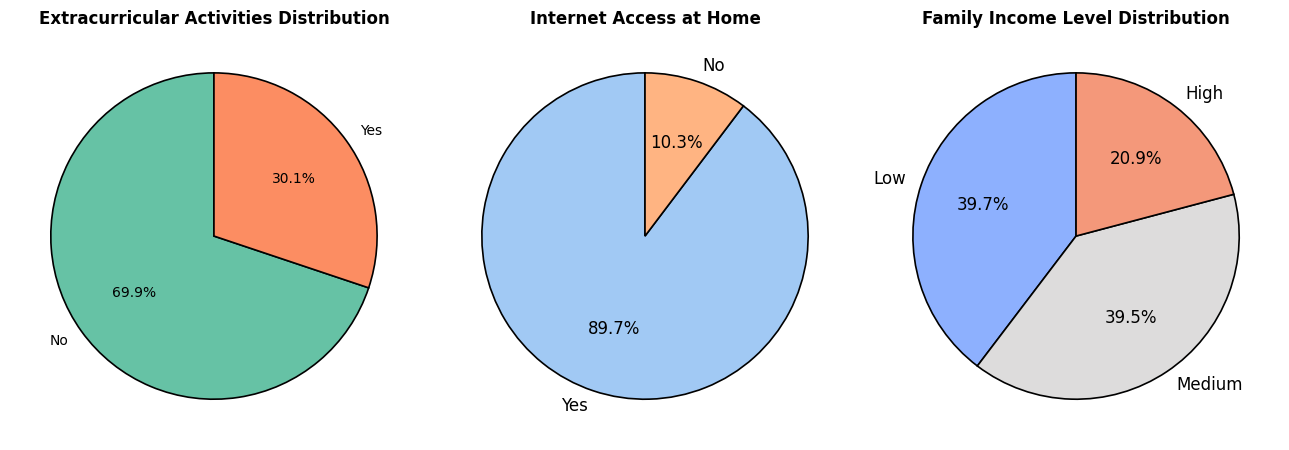
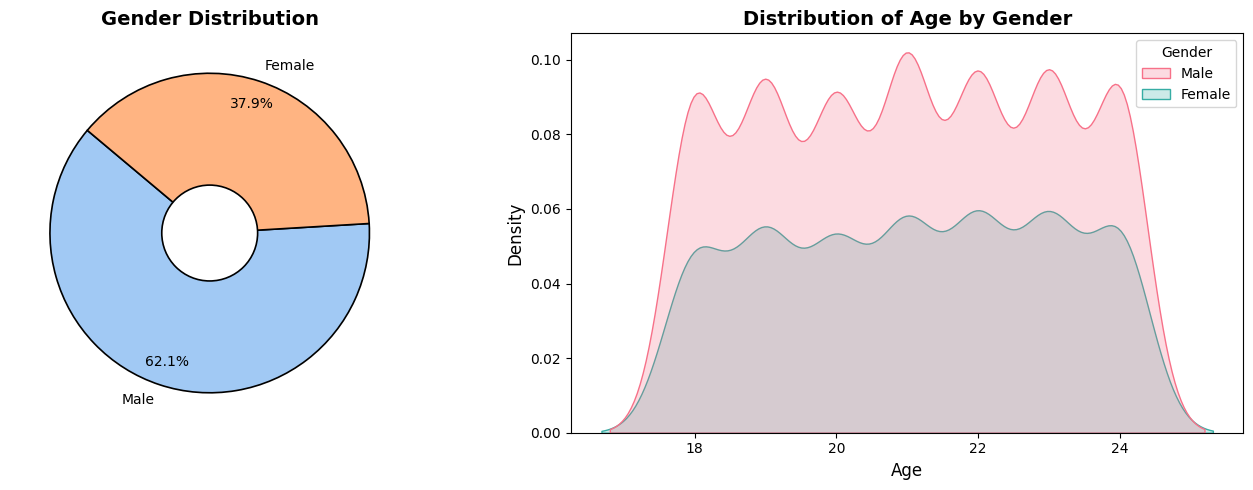
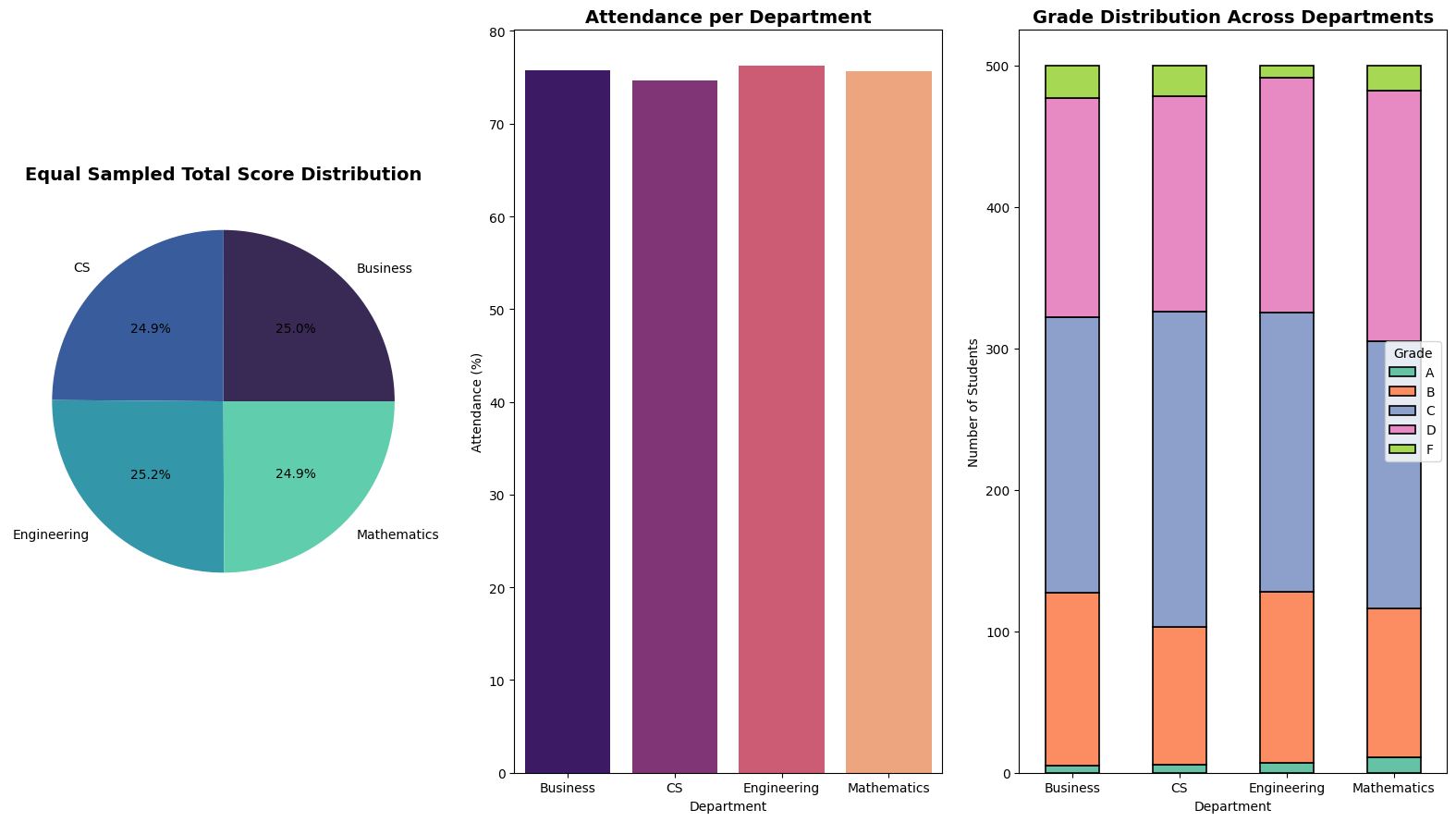
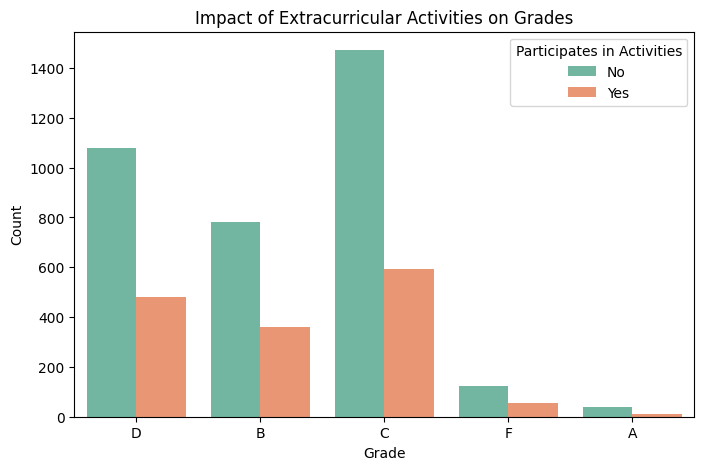
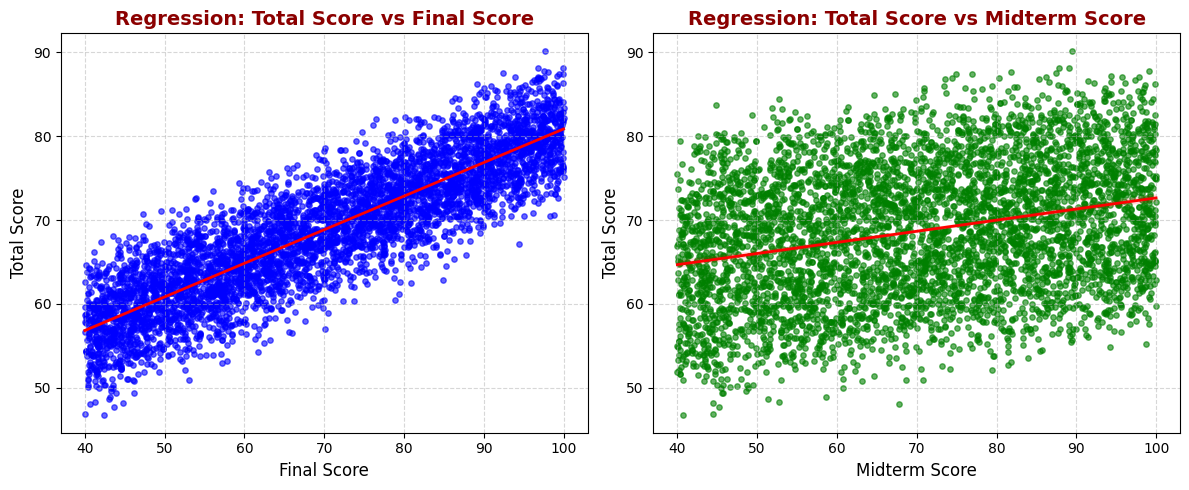
In this project, we are working with the Students Grading Dataset from Kaggle. Our primary focus is on data cleaning and exploratory data analysis (EDA) rather than prediction. The goal is to understand the structure of the dataset, handle missing values, detect outliers, and uncover key patterns in student performance.
By analyzing various factors such as attendance, participation, previous scores, and demographics, we aim to gain insights into how these attributes influence student grades. Instead of building a predictive model, this project will serve as a foundation for future machine learning applications by ensuring the dataset is clean and well-explored.